

Задачи классификации для текстов¶
- Анализ тональности текста
- Фильтрация спама
- Определение языка документа

Задачи классификации для текстов¶
- Анализ тональности текста
- Фильтрация спама
- Определение языка документа
- Проставление тегов документам
Работа с разреженными данными¶
Существует много типов разреженных матриц, каждый из которых предоставляет разные гарантии на операции.
scipy.sparse.bsr_matrixscipy.sparse.coo_matrixscipy.sparse.csc_matrixscipy.sparse.csr_matrixscipy.sparse.dia_matrixscipy.sparse.dok_matrixscipy.sparse.lil_matrix
Подробнее про разреженые матрицы
Конкатенация¶
Для разреженных матриц есть свои hstack и vstack, которые находятся в scipy.sparse
Что можно использовать?¶
Подходят почти все модели
- LogisticRegression
- LinearSVC
- MultinomialNB
- RandomForestClassifier
- KNeighborsClassifier
Не подходят
- GradientBoostingClassifier
Пример задачи¶
- 10 тысяч вопросов со StackOverflow
- Каждый вопрос имеет либо тег windows, либо тег linux.
Мы хотим по тексту вопроса определить его тег.
texts = pd.read_csv('windows_vs_linux.10k.tsv', header=None, sep='\t')
texts.columns = ['text', 'is_windows']
print(texts.shape)
texts.head(4)
Bag of words¶
В качестве признаков будем использовать факт вхождения слова в документ.
vectorizer = CountVectorizer(binary=True)
bow = vectorizer.fit_transform(texts.text)
print(bow.shape)
print(type(bow))
Выбор модели и оценка¶
- Будем использовать LogisticRegression
- "C" подберём с помощью GridSearchCV
params = {'C': np.logspace(-5, 5, 11)}
clf = LogisticRegression()
cv = GridSearchCV(clf, params, n_jobs=-1, scoring='roc_auc', cv=5)
cv.fit(bow, texts.is_windows);
Выбор модели и оценка¶
- $AUC = 0.965813$
- Довольно простая задача для случая из двух тегов
pd.DataFrame(cv.cv_results_)[['mean_test_score', 'params']].sort_values('mean_test_score', ascending=False)
Получение слов с наибольшим весом¶
top = pd.DataFrame([get_top_windows(cv.best_estimator_, 6),
get_top_linux(cv.best_estimator_, 6)]).T
top.columns = ['Windows', 'Linux']
top
Отбор признаков¶
Представим, что у нас есть очень много признаков и мы хотим сократить их количество, выбрав только самые нужные.
В данном случае мы взяли все возможные $N$-граммы, где $N \in \{1, \dots, 4\}$
vectorizer = CountVectorizer(binary=True, ngram_range=(1, 4))
bow = vectorizer.fit_transform(texts.text)
print(bow.shape)
print(type(bow))
Выбираем признаки¶
Мы можем отобрать $50000$ признаков с помощью SelectKBest и увидеть, что мы получили на кросс-валидации качество лучше чем до этого.
Есть ли тут проблемы?
k_best = SelectKBest(k=50000)
bow_k_best = k_best.fit_transform(bow, texts.is_windows)
clf = LogisticRegression()
np.mean(cross_val_score(clf, bow_k_best, texts.is_windows, scoring='roc_auc', cv=5))
Проверка¶
Когда делается отбор признаков всегда нужна проверка на отложенной выборке, иначе оценка будет сильно завышена.
x_train, x_test, y_train, y_test = train_test_split(bow, texts.is_windows)
print(x_train.shape)
print(x_test.shape)
k_best = SelectKBest(k=50000)
x_train_k_best = k_best.fit_transform(x_train, y_train)
x_test_k_best = k_best.transform(x_test)
clf = LogisticRegression()
clf.fit(x_train_k_best, y_train)
roc_auc_score(y_test, clf.predict_proba(x_test_k_best)[:, 1])
AUC¶
- Метрика для бинарной классификации
- Важен порядок ответов, а не сами значения
y_hat = cross_val_predict(cv.best_estimator_, bow, texts.is_windows, method='predict_proba')[:, 1]
y_hat[:5]
Делая любое преобразование, сохраняющее порядок, мы будет получать одинаковое значение $AUC$
print(roc_auc_score(texts.is_windows, y_hat))
print(roc_auc_score(texts.is_windows, y_hat * 2 + 1))
print(roc_auc_score(texts.is_windows, y_hat ** 2))
AUC — Area under curve¶
fpr, tpr, _ = roc_curve(texts.is_windows, y_hat)
plot(fpr, tpr, lw=2);
plot([0, 1], [0, 1], linestyle='--');
xlim([0.0, 1.0])
ylim([0.0, 1.05])
xlabel('False Positive Rate')
ylabel('True Positive Rate');

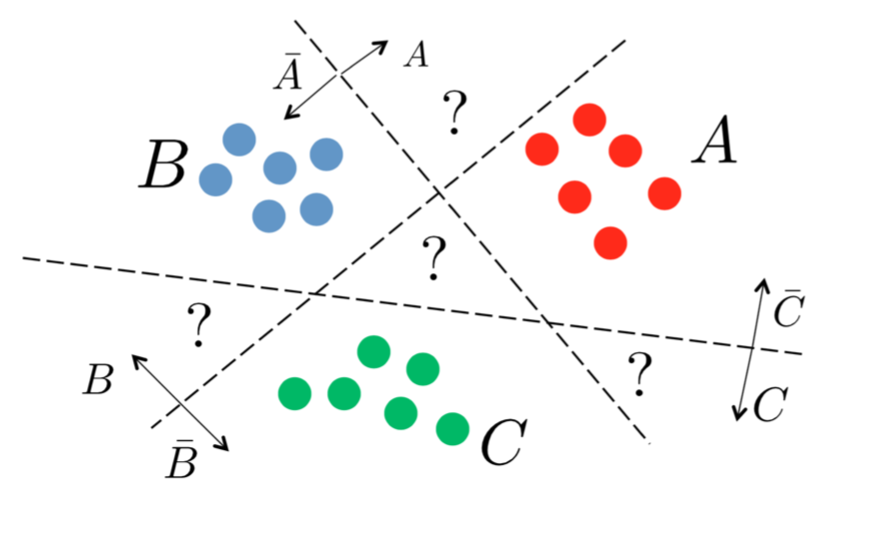
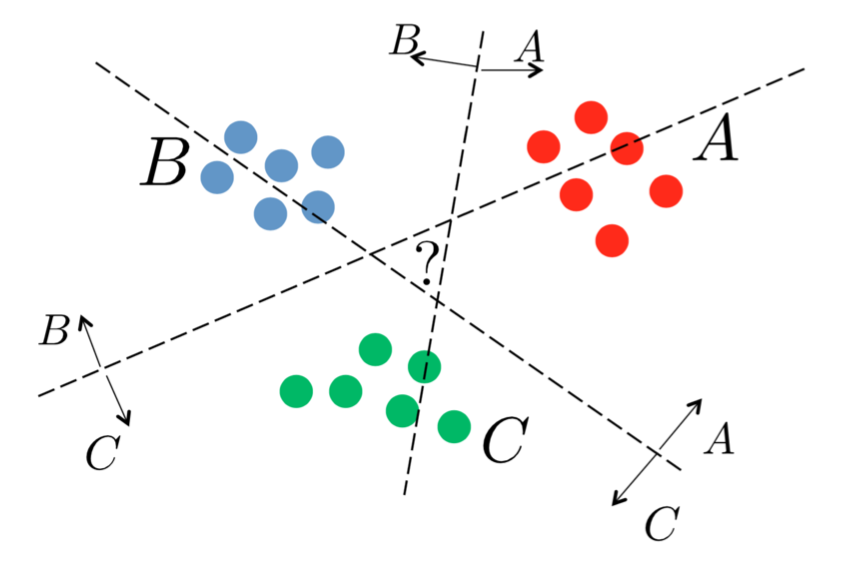
Многоклассовая классификация¶
- Каждый вопрос имеет несколько тегов
- По тексту нужно определить все теги для каждого вопроса
texts = pd.read_csv('multi_tag.10k.tsv', header=None, sep='\t')
texts.columns = ['text', 'tags']
print(texts.shape)
texts.head(4)
Обощение бинарной классификации¶
Некоторые методы умеют работать с несколькими метками из коробки
KNeighborsClassifierRandomForestClassifierSVC
Остальные можно обобщить с помощью обучения нескольких моделей
OneVsRestClassifierOneVsOneClassifier
Оценка качества¶
- Для нескольких классов $AUC$ не подходит
- Будем использовать обобщение $F$—меры на несколько классов
$tp$, $fp$ и $fp$ будут считаться по всем тегам одного объекта
y, y_hat = np.array([[1, 1, 0, 0]]), np.array([[1, 0, 1, 0]])
tp, fp, fn = 1., 1., 1.
p, r = tp / (tp + fp), tp / (tp + fn)
f1 = 2 * p * r / (p + r)
print(f1)
print(f1_score(y, y_hat, average='samples'))
Bag of words¶
Повторим всё, как для случая двух классов
vectorizer = CountVectorizer(binary=True)
bow = vectorizer.fit_transform(texts.text)
print(bow.shape)
print(type(bow))
Отбор тегов¶
- Оставим только самые популярные 20 тегов для предсказания
- Если у вопроса после такой фильтрации не осталось тегов, то присвоим ему отдельный тег other
tags = texts.tags.apply(lambda x: x.split())
all_tags = reduce(lambda s, x: s + x, tags, [])
values, count = np.unique(all_tags, return_counts=True)
top_tags = sorted(zip(count, values), reverse=True)[:20]
top_tags[:5]
Преобразуем списки тегов в матрицу, которая будет содержать индикаторы наличия тега у вопроса.
binarizer = MultiLabelBinarizer()
y = binarizer.fit_transform(texts.tags.apply(lambda x: filter_tags(x.split())))
print(y.shape)
print(type(y))
Выбор модели и оценка¶
- Также будет использовать
LogisticRegression, но уже вместе сOneVsRestClassifier
params = {'estimator__C': np.logspace(-5, 5, 11)}
clf = OneVsRestClassifier(LogisticRegression())
cv = GridSearchCV(clf, params, n_jobs=-1, scoring=make_scorer(f1_score, average='samples'), cv=5)
cv.fit(bow, y);
Выбор модели и оценка¶
- $F1 = 0.4047323$
- Как видно задача стала существенно сложней
- Попробуем улучшить качество
pd.DataFrame(cv.cv_results_)[['mean_test_score', 'params']].sort_values('mean_test_score', ascending=False)
Tf-Idf¶
- Вместо бинарного значения, для каждого слова считается его вес
- Обычно работает лучше, чем
CountVectorizer
vectorizer = TfidfVectorizer()
tf_idf = vectorizer.fit_transform(texts.text)
print(tf_idf.shape)
print(type(tf_idf))
Выбор модели и оценка¶
Ищем лучшие параметры
params = {'estimator__C': np.logspace(-5, 5, 11)}
clf = OneVsRestClassifier(LogisticRegression())
cv = GridSearchCV(clf, params, n_jobs=-1, scoring=make_scorer(f1_score, average='samples'), cv=5)
cv.fit(tf_idf, y);
Выбор модели и оценка¶
- $F1=0.382173$
- Получилось хуже, чем BOW.
- Но почему?
pd.DataFrame(cv.cv_results_)[['mean_test_score', 'params']].sort_values('mean_test_score', ascending=False)
Выбор порога¶
- При вызове
predictвозвращается 1, если вероятность принадлежности к классу больше $0.5$ - Можно выбирать порог самому через кросс-валидацию
clf = OneVsRestClassifier(LogisticRegression(C=100000))
y_hat_bow = cross_val_predict(clf, bow, y, method='predict_proba')
y_hat_tf_idf = cross_val_predict(clf, tf_idf, y, method='predict_proba')
Функция, которая в зависимости от порога ставит тег
def get_score(alpha, y, y_hat):
return f1_score(y, (y_hat > alpha).astype('int'), average='samples')
Выбор порога для BOW¶
- Качество с порогом по умолчанию — $F1=0.404732$
- Качество с подобранным порогом — $F1=0.454356$
alphas = np.linspace(0.0, 0.01, 100)
scores = [get_score(alpha, y, y_hat_bow) for alpha in alphas]
plot(alphas, scores);
scatter(alphas[np.argmax(scores)], np.max(scores));
print(np.max(scores))
print(alphas[np.argmax(scores)])

Выбор порога для Tf-Idf¶
- Качество с порогом по умолчанию — $F1=0.382173$
- Качество с подобранным порогом — $F1=0.493972$
alphas = np.linspace(0.0, 0.01, 100)
scores = [get_score(alpha, y, y_hat_tf_idf) for alpha in alphas]
plot(alphas, scores);
scatter(alphas[np.argmax(scores)], np.max(scores));
print(np.max(scores))
print(alphas[np.argmax(scores)])

N-граммы¶
- При увеличении N количество признаков стремительно растёт
- Даже для 10 тысяч объектов валидация и подбор гиперпараметров существенно замедляются
vectorizer = CountVectorizer(binary=True, ngram_range=(1, 3))
bow = vectorizer.fit_transform(texts.text)
print(bow.shape)
print(type(bow))
Hashing Trick¶
Вместо того, чтобы хранить каждый вариант N-граммы отдельно, мы будем получать индекс столбца, хешируя содержимое.
Позволяет задавать произвольное количество столбцов.
vectorizer = HashingVectorizer(binary=True, ngram_range=(1, 3), n_features=50000)
bow = vectorizer.fit_transform(texts.text)
print(bow.shape)
print(type(bow))
Выбор порога для HashingTrick¶
- Качество с подобранным порогом — $F1=0.509255$
clf = OneVsRestClassifier(LogisticRegression(C=100000))
y_hat_bow = cross_val_predict(clf, bow, y, method='predict_proba')
alphas = np.linspace(0.0, 0.01, 100)
scores = [get_score(alpha, y, y_hat_bow) for alpha in alphas]
plot(alphas, scores);
scatter(alphas[np.argmax(scores)], np.max(scores));
print(np.max(scores))
print(alphas[np.argmax(scores)])

Понижение размерности¶
Можно получать dense матрицы любым способом, который вам нравится.
Позволяет сократить время обучения и использовать методы, которые больше подходят dense матрицы.
vectorizer = TfidfVectorizer(ngram_range=(1, 2))
tf_idf = vectorizer.fit_transform(texts.text)
print(tf_idf.shape)
print(type(tf_idf))
svd = TruncatedSVD(n_components=200, n_iter=5)
tf_idf_svd = svd.fit_transform(tf_idf)
Блендинг¶
Когда у нас есть несколько моделей, мы можем получать смешенное предсказание.
Если модели не сильно скоррелированы, то зачастую мы можем улучшить качество результирующей модели.
vectorizer = HashingVectorizer(binary=True, ngram_range=(1, 3), n_features=50000)
bow = vectorizer.fit_transform(texts.text)
print(bow.shape)
print(type(bow))
vectorizer = TfidfVectorizer()
tf_idf = vectorizer.fit_transform(texts.text)
print(tf_idf.shape)
print(type(tf_idf))
Предсказания¶
С помощью кросс-валидации предскажем обучающую выборку для каждой модели.
В итоге мы получим несмещённые предсказания для объектов, у которых уже знаем метки.
clf_lr = OneVsRestClassifier(LogisticRegression(C=100000))
y_hat_lr = cross_val_predict(clf_lr, bow, y, method='predict_proba', cv=folds)
clf_lr = OneVsRestClassifier(LogisticRegression(C=100000))
y_hat_lr_tf_idf = cross_val_predict(clf_lr, tf_idf, y, method='predict_proba', cv=folds)
Оценка¶
Получим качество на каждой моделе в отдельности и на их смеси.
- Качество первой модели — $F1=0.5092$
- Качество второй модели — $F1=0.4935$
- Качество их смеси — $F1=0.5270$
alphas = np.linspace(0.0, 0.02, 100)
lr_scores = [get_score(alpha, y, y_hat_lr) for alpha in alphas]
nb_scores = [get_score(alpha, y, y_hat_lr_tf_idf) for alpha in alphas]
lr_nb_scores = [get_score(alpha, y, 0.5 * y_hat_lr_tf_idf + 0.5 * y_hat_lr) for alpha in alphas]
print(np.max(lr_scores))
print(np.max(nb_scores))
print(np.max(lr_nb_scores))
plot(alphas, lr_scores);
plot(alphas, nb_scores);
plot(alphas, lr_nb_scores);
scatter(alphas[np.argmax(lr_scores)], np.max(lr_scores));
scatter(alphas[np.argmax(nb_scores)], np.max(nb_scores));
scatter(alphas[np.argmax(lr_nb_scores)], np.max(lr_nb_scores));

Стекинг¶
Вместо ручного смешивания результатов мы можем подавать их на вход другим алгоритмам.
Подготовим переменную stacked, которая будет содержать предсказания предыдущих алгоритмов
stacked = np.hstack([y_hat_lr, y_hat_lr_tf_idf])
clf_stacked = OneVsRestClassifier(RandomForestClassifier(n_estimators=100))
y_hat_stacked = cross_val_predict(clf_stacked, stacked, y, method='predict_proba', cv=folds)
Оценка¶
После подбора порога получим $F1=0.547874$, что больше всех предыдущих результатов.
alphas = np.linspace(0, 1, 100)
scores = [get_score(alpha, y, y_hat_stacked) for alpha in alphas]
plot(alphas, scores);
scatter(alphas[np.argmax(scores)], np.max(scores));
print(np.max(scores))
print(alphas[np.argmax(scores)])

Больше про стекинг¶
Почти во всех конкурсах так или иначе используется стекинг или блендинг, поэтому очень важно понимать как они работают и как их использовать.
VW¶
- Разработка Yahoo и потом Microsoft
- Библиотека и CLI программа, позволяющая строить линейные модели
- Способна обрабатывать миллиарды объектов с сотнями тысяч признаков
Проверяем VW¶
!vw -h
Формат ввода¶
- Использует необычный формат входных данных
Label [weight] |Namespace Feature ... |Namespace ...Label— метка класса для задачи классификации или действительное число для задачи регрессииweight— вес объекта, по умолчанию у всех одинаковыйNamespace— все признаки разбиты на области видимости, может использоваться для раздельного использования или создания квадратичных признаков между областямиFeature—string[:value]илиint[:value]строки будут хешированы, числа будут использоваться как индекс в векторе признаков.valueпо умолчанию равно $1$
Hashing trick¶
Вводится функция $h$, с помощью которой получается индекс для записи значения в вектор признаков объекта.
$$h : F \rightarrow \{0, \dots, 2^b - 1\}$$С помощью --b можно задавать размер области значений хеш-функции.
Optimization¶
Может использовать SGD или L-BFGS
SGDпо умолчанию, позволяет делать онлайн обучение. Почти всегда необходимо несколько проходов по данным.L-BFGSвключается с помощью--bfgs, работает только с данными небольшого размера- Количество проходов для
SGDзадаётся с помощью параметра--passes
Параметры оптимизации¶
Проходим по всем элементам обучающей выборки много раз, на каждом объекте делаем поправку весов:
Здесь $t$ — порядковый номер объекта обучения, $k$ — номер прохода по всей выборке.
- $\lambda$:
-l(learning rate) - $d$:
--decay_learning_rate - $t_0$:
--initial_t - $p$:
--power_t - $k_{max}$:
--passes
Оценка качества¶
average loss — loss by progressive validation
$e_i$ — loss на объекте $x_i$ при обучении на объектах $\{x_1 ... x_{i-1}\}$
Примеры для бинарной классификации¶
- Два класса с признаками A и B
-1 | A:1 B:10 1 | A:-1 B:12
- Можно использовать текст без обработки
-1 | so i find myself porting a game that was originally written 1 | i ve been using tortoisesvn in a windows environment for quite some time
Попробуем решить windows vs linux¶
Для этого сначала сконвертируем данные в формат для vw
texts = pd.read_csv('windows_vs_linux.10k.tsv', sep='\t', header=None)
texts[1].replace({0: '-1 ', 1: '1 '}, inplace=True)
train_texts, test_texts = train_test_split(texts)
train_texts[[1, 0]].to_csv('win_vs_lin.train.vw', sep='|', header=None, index=False)
test_texts[[1, 0]].to_csv('win_vs_lin.test.vw', sep='|', header=None, index=False)
!head -n 5 win_vs_lin.train.vw | cut -c 1-50
Обучение¶
!vw -d win_vs_lin.train.vw --loss_function logistic -P 10000 -f model.vw --passes 100 -c
Применение¶
!vw -i model.vw -t -p output.csv win_vs_lin.test.vw --loss_function logistic
Результат¶
y_hat = pd.read_csv('output.csv', header=None)
roc_auc_score(test_texts[1].replace({'-1 ': 0, '1 ': 1}), y_hat[0])
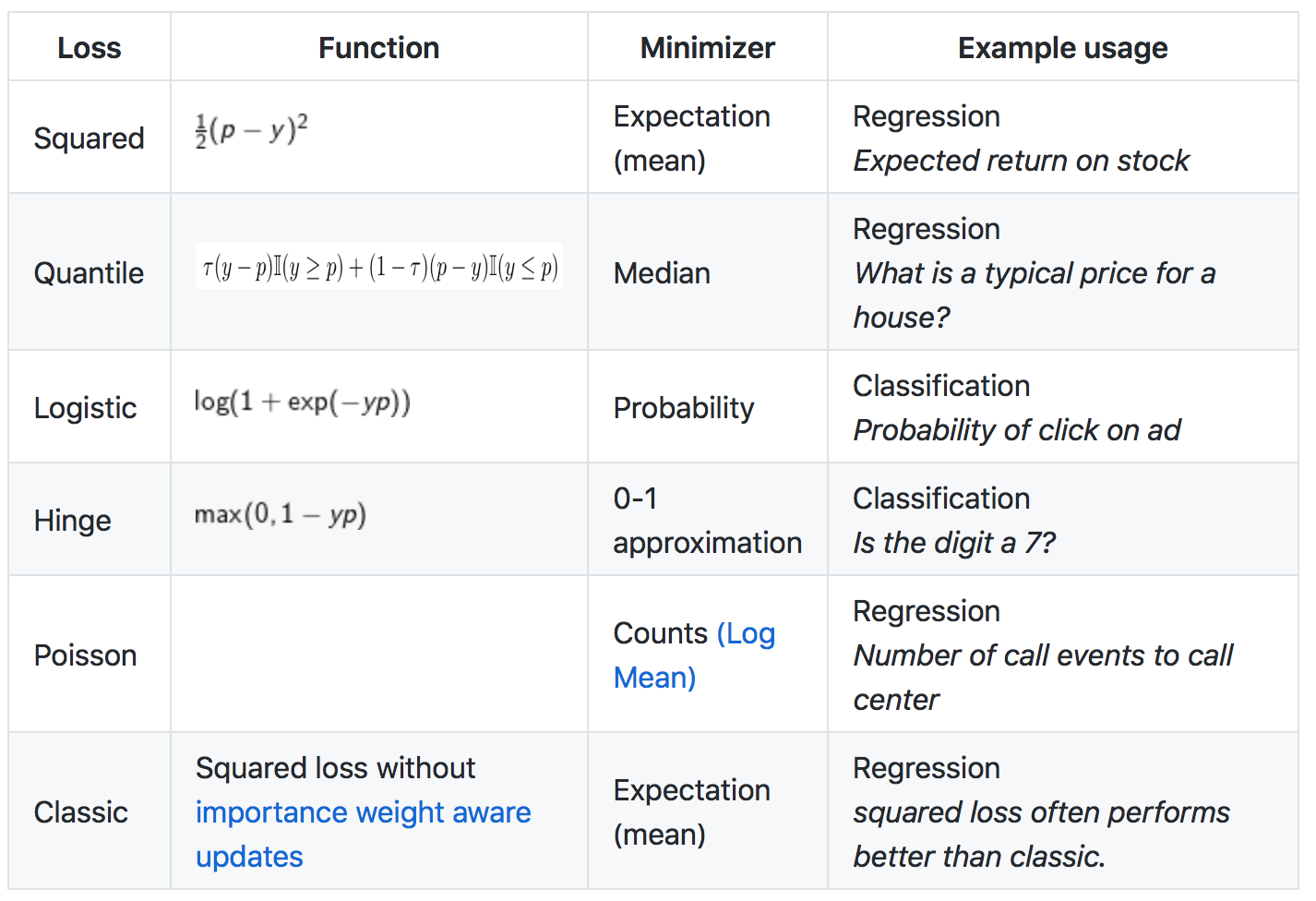
Многоклассовая классификация¶
Включается с помощью флага --multilabel_oaa n, где $n$ число классов
texts = pd.read_csv('multi_tag.10k.tsv', header=None, sep='\t')
texts.columns = ['text', 'tags']
classes = np.arange(21)
texts['tags'] = map(lambda row: ','.join(map(str, classes[row.astype('bool')])) + ' ', y)
texts[['tags', 'text']].to_csv('multi_tag.vw' , sep='|', header=None, index=False)
!head -n 5 multi_tag.vw | cut -c 1-80
Обучение¶
!vw -d multi_tag.vw --loss_function logistic -f model.vw --multilabel_oaa 21 --passes 10 -c
Предсказание¶
Для простоты получим ответы на train
!vw -i model.vw -p output.csv multi_tag.vw --loss_function logistic
Конкурсы по анализу данных¶
- Организаторы конкурсов выдают данные
- Обучающую выборку с ответами
- Тестовую выборку без ответов
- Каждый участник создаёт модель локально
- Нет никаких ограничений на модель
- Сравниваются только результаты на тестовой выборке
Kaggle-in-class¶
- Платформа для учебных соревнований
- До окончания соревнования виден только публичный скорборд, который считается по меньшей части тестовой выборки
- После окончания соревнования в приватный скорборд берутся только несколько попыток из участвующих в публичном
Конкурс¶
- Вам дана информация о документах и их тегах
- Всего 30000 документов и 98 тегов
- Для каждой пары документ-терм известен её вес
- Метрика такая же как в примере со stackoverflow — Mean F1
Безлайны¶
- Мы выдаём безлайн, с помощью которого можно воспроизвести базовое решение
- Также есть более сложный безлайн — medium baseline, код от которого не выдаётся
Оценивание¶
- +5 баллов — за получение решения, которое лучше чем medium baseline до наступления промежуточного дедлайна
- +30 баллов — за первое место
- +25 баллов — за второе место
- +20 баллов — за третье место
Правила игры¶
- 5 попыток в день
- Решать задания необходимо в одиночку
- Можно выбрать только две попытки в конце конкурса
- Дедлайн по конкурсу — 24 апреля в 9:00
- Промежуточный дедлайн — 3 апреля в 9:00
- Запрещается использование внешних наборов данных, не предоставленных на соревновании